
KI-Chatbots sind in aller Munde, und jeder Anbieter möchte hier mitmischen, gerade erst Microsoft mit seinem „Copilot“-System.
Aber was, wenn du dir einen privaten Chatbot wünschst, ohne dass dieser Daten an den Hersteller schickt oder du spezielle Hardware benötigst?
Ja, das ist absolut möglich und funktioniert mit LM Studio auch sehr einfach. In diesem Artikel sehen wir uns an, wie das geht!
Mit jeder CPU/GPU!
Prinzipiell läuft der Chatbot, den wir uns hier ansehen, auf „jedem“ System. Lediglich muss deine CPU den AVX2-Standard unterstützen (was fast alle Intel-CPUs ab Baujahr 2013 und AMD-CPUs ab 2015 tun sollten). Mehr Infos zum AVX2-Standard findst du hier: https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#CPUs_with_AVX2
Was wir aber brauchen, ist recht viel RAM. 16 GB sind hier das Minimum, aber große Modelle können auch gerne mal 64 GB+ verbrauchen.
Die Software LM Studio
Es gibt viele Möglichkeiten, lokale KI-Chatbots auszuführen. Die vermutlich einfachste ist aber LM Studio.
LM Studio gibt es für Windows, Mac und Linux und lässt sich mit einem Klick installieren. Das Besondere an LM Studio ist, dass es keine eigene KI mitbringt, sondern öffentliche KI-Modelle, beispielsweise von Meta oder Google, herunterladen und ausführen kann.

Hierfür greift es auf https://huggingface.co/models zurück, eine Plattform, die verschiedene KI-Modelle sammelt und zum Download anbietet.
LM Studio arbeitet mit KI-Modellen auf Basis von Llama, Gemma, Phi 3, Falcon, Mistral und StarCoder zusammen.
Llama 3 ist dabei das KI-Modell von Facebook (Meta) und Gemma (2) das KI-Modell, das hinter Googles Chat-Assistenten steht.
Dabei stehen auch diverse von Nutzern modifizierte Versionen für bestimmte Zwecke zur Verfügung, welche teilweise Zensurmaßnahmen aushebeln oder besonders fürs Coden optimiert sind usw.
Erste Schritte
Du hast LM Studio heruntergeladen und installiert, wie geht es weiter? Im ersten Schritt solltest du dir ein KI-Modell aussuchen, mit dem du starten möchtest.
In LM Studio gibt es eine Suchfunktion, in der du ein Stichwort eingeben kannst, z. B. „Coding“, „Chat“ oder etwas Gezielteres wie „Llama“ oder „Gemma“.
Für diesen Artikel nehme ich ein auf Llama basierendes Modell. Hier werden dir dutzende Modelle dieser Art auffallen. Dies sind die angesprochenen „Versionen“, die von anderen Nutzern auf Basis der großen KI-Modelle erstellt wurden.
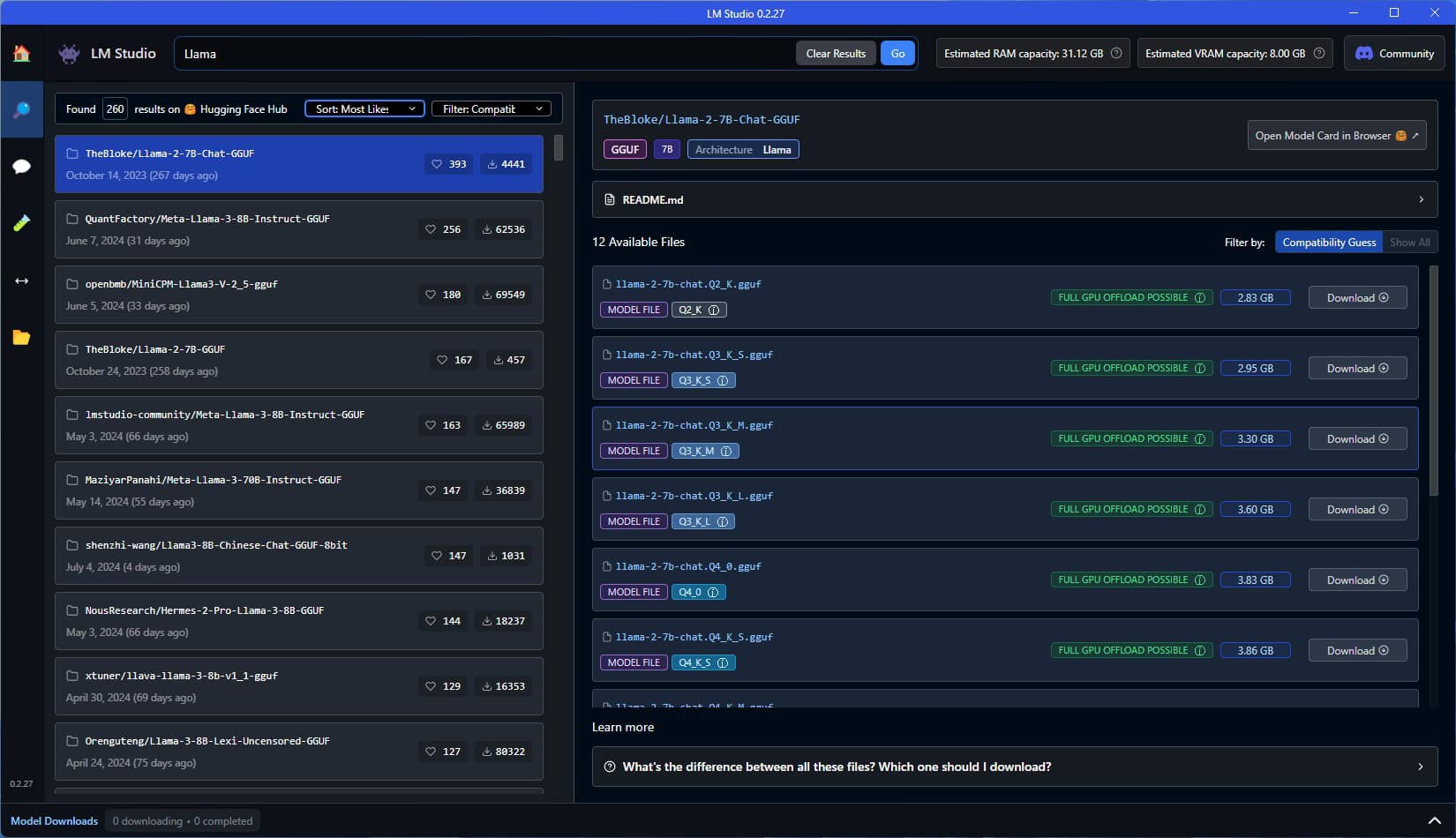
Hier gilt oft das Motto „Probieren geht über Studieren“.
Welches Modell nehmen?
Direkt auf der Startseite von LM Studio werden dir diverse Modelle angeboten, wie z. B. Llama 3 – 8B Instruct oder Google’s Gemma 2B Instruct usw.
Mit diesen Modellen machst du natürlich nichts falsch. Ich würde aber auf die Suche gehen (links das Icon mit der Lupe) und dort z. B. „Llama“ eingeben.
Hier werden dir diverse Modelle angeboten und es gibt jeweils nochmals Abstufungen. Diese sind beispielsweise mit Q4, Q5, Q6, Q8 usw. beschriftet.
Q steht hier für Quantization, was wir als eine Art Kompression von KI-Modellen ansehen können. Je kleiner die Zahl, desto stärker ist das Modell „komprimiert“ und „reduziert“. Entsprechend werden natürlich die Antworten schlechter, je kleiner die Zahl ist, aber die Modelle laufen besser und benötigen weniger RAM/Speicher.
Beispielsweise nutze ich hier jetzt das „QuantFactory/Meta-Llama-3-8B-Instruct-GGUF“-Modell, welches in der Q8-Version 8,54 GB groß ist, was auch +- dem RAM-Bedarf entspricht.
Du solltest hier kein Modell nehmen, welches den freien RAM deines PCs übersteigt, da dieses abstürzen wird.
Persönlich habe ich mit den Llama-3-Modellen die beste Erfahrung gemacht. Eine kleine verallgemeinerte Übersicht:
Llama:
- Entwickelt von Meta (Facebook)
- Open-Source-Modell, d. h. der Code ist öffentlich zugänglich und kann von Entwicklern angepasst werden
- Vielseitig einsetzbar, z. B. für kreatives Schreiben, Übersetzungen, Codegenerierung, Smalltalk
- Stark in der Anpassungsfähigkeit: Kann leicht auf spezifische Aufgaben oder Datensätze trainiert werden
Gemma:
- Entwickelt von Google
- Basiert auf der gleichen Technologie wie Googles Gemini-Modelle
- Fokus auf Textverständnis und -generierung
- Besonders gut in Aufgaben wie Fragen beantworten, Zusammenfassungen und Schreiben
Llama ist flexibler, teils kreativer und anpassungsfähiger, während Gemma Stärken besonders beim Programmieren, Sprachverständnis und -generierung zeigt. Dies ist aber natürlich stark verallgemeinert, und gerade bei Llama gibt es viele speziell für gewisse Anwendungen angepasste Modelle.
Im Chat-Fenster
Das Chat-Fenster ist selbsterklärend. Oben wählst du das aktuelle Modell aus, das LM Studio nutzt, und unten gibst du deine Nachrichten ein.
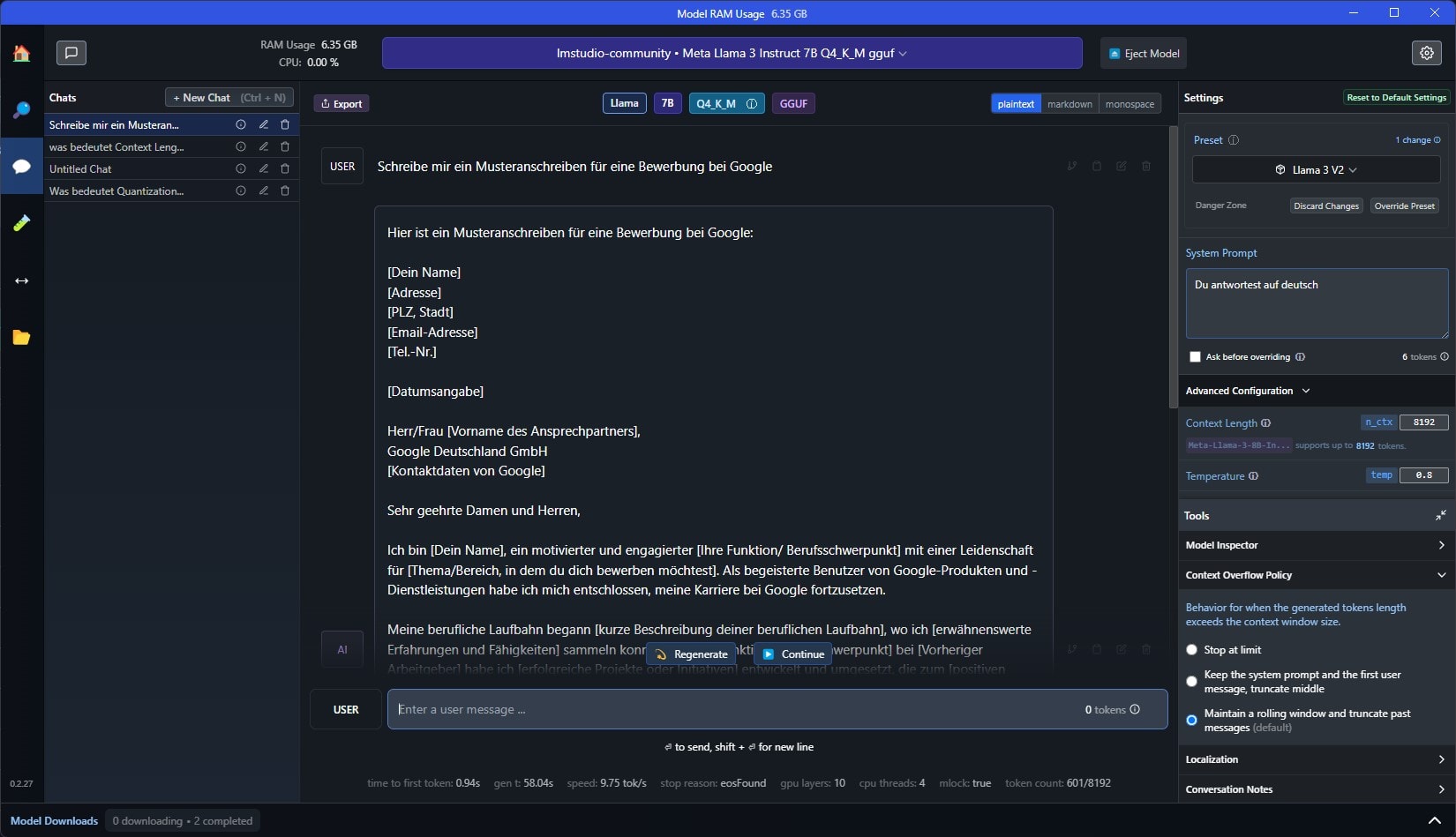
Fertig! Nun sollte das System eine Antwort ausgeben. Allerdings gibt es ein paar Einstellungen, die du vornehmen könntest/solltest.
System Prompt
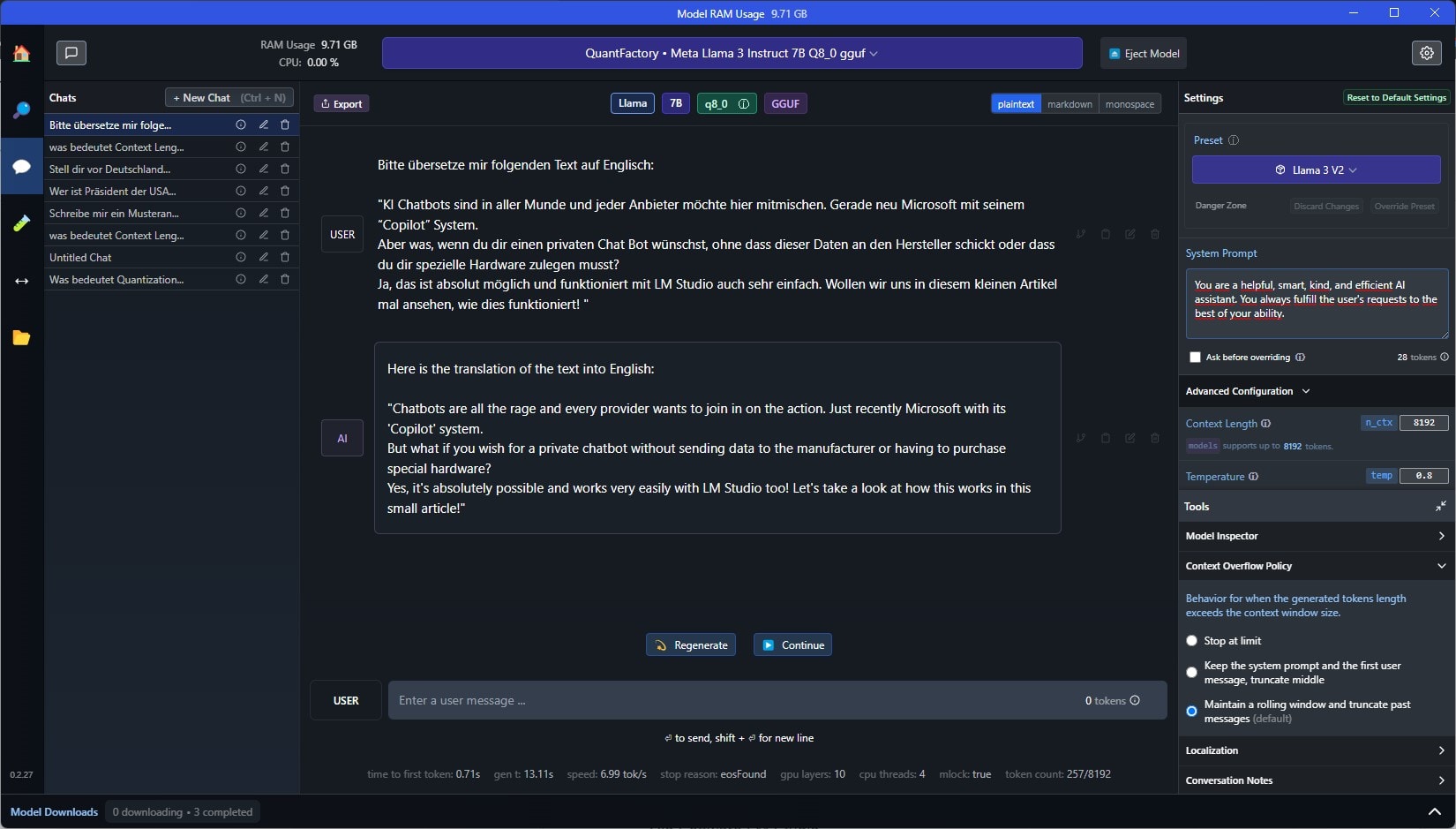
Im Fenster „System Prompt“ kannst du eine Art allgemeine, übergreifende Anweisung einfügen, beispielsweise „Du antwortest immer auf Deutsch“ oder, falls du irgendwelche anderen Charaktereigenschaften der KI festlegen willst, wie „Antworte besonders freundlich“ oder ähnliches.
Context Length
Die „Context Length“ definiert das „Erinnerungsvermögen“ der KI. Also wie viele Wörter, Befehle usw. du ihr in einer Konversation gegeben hast, die sich die KI für weitere Interaktionen gemerkt hat. Übersteigt die Context Length das festgelegte Limit, kann es passieren, dass die KI vorherige Informationen vergisst oder allgemein nur noch Unsinn ausgibt.
Die Context Length kannst du unter „Advanced Configuration“ festlegen und sollte dort im besten Fall immer dem Maximum des jeweiligen Modells entsprechen, meist 8192.
Weitere Einstellungen
Es gibt noch weitere Einstellungen unter „Advanced Configuration“, wie die Temperatur usw., welche du aber nicht zwingend verändern musst. Diese verändern primär, wie „kreativ“ die KI ist usw.
Wie hoch ist die Performance?
Zwar läuft LM Studio auf fast jedem Rechner, sofern du ausreichend RAM hast, aber die Performance steht natürlich auf einem anderen Blatt.
Hast du eine fähige Grafikkarte mit viel VRAM, dann antworten auch größere Modelle prompt. Hast du nur eine integrierte GPU und vielleicht einen schwachen Prozessor, können durchaus Minuten vergehen, bis eine Antwort kommt, vor allem, wenn du größere Modelle nutzt.
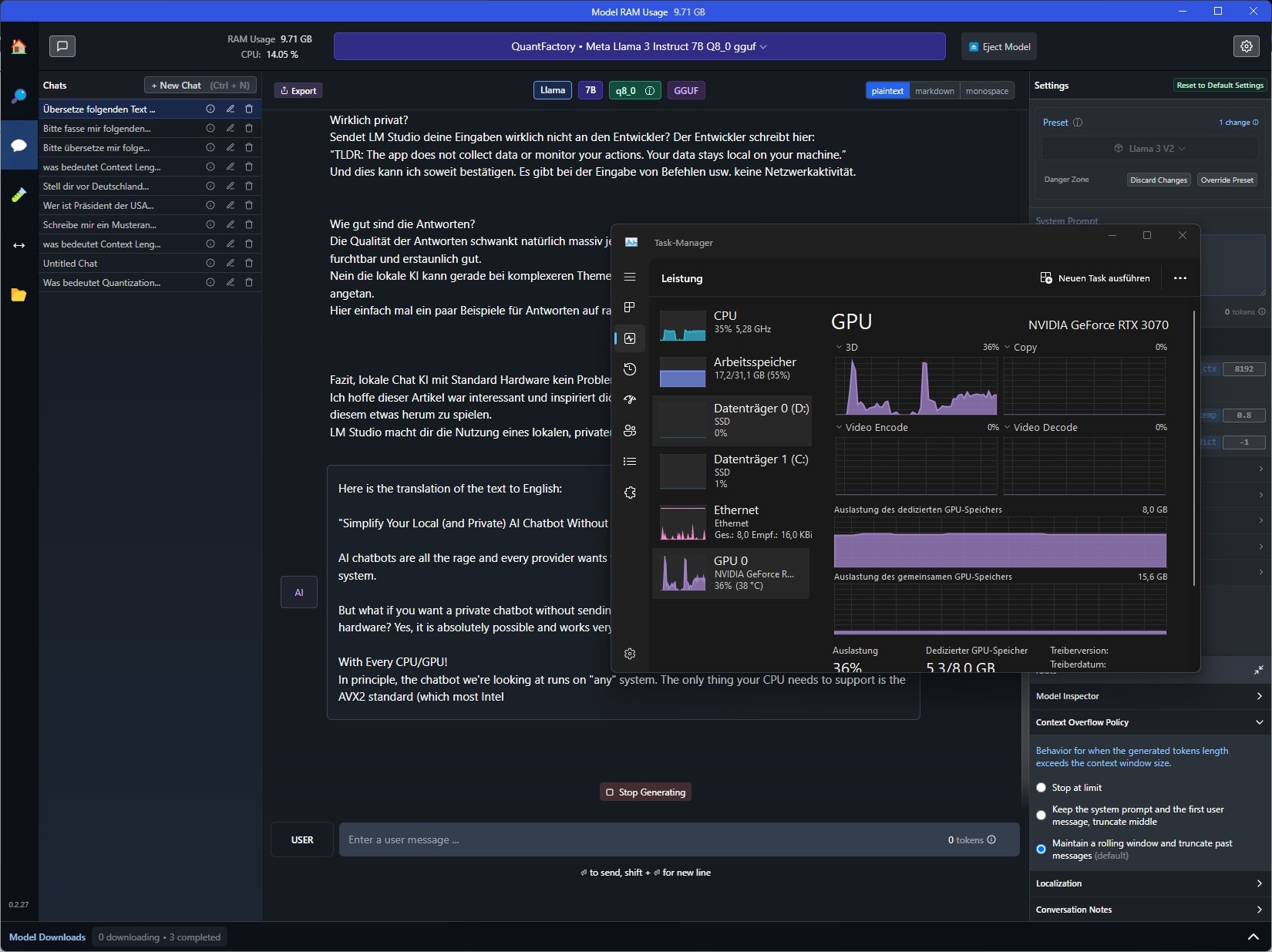
Allerdings habe ich die Erfahrung gemacht, dass die meisten KI-Chatbots auf aktuellen Systemen erstaunlich gut laufen.
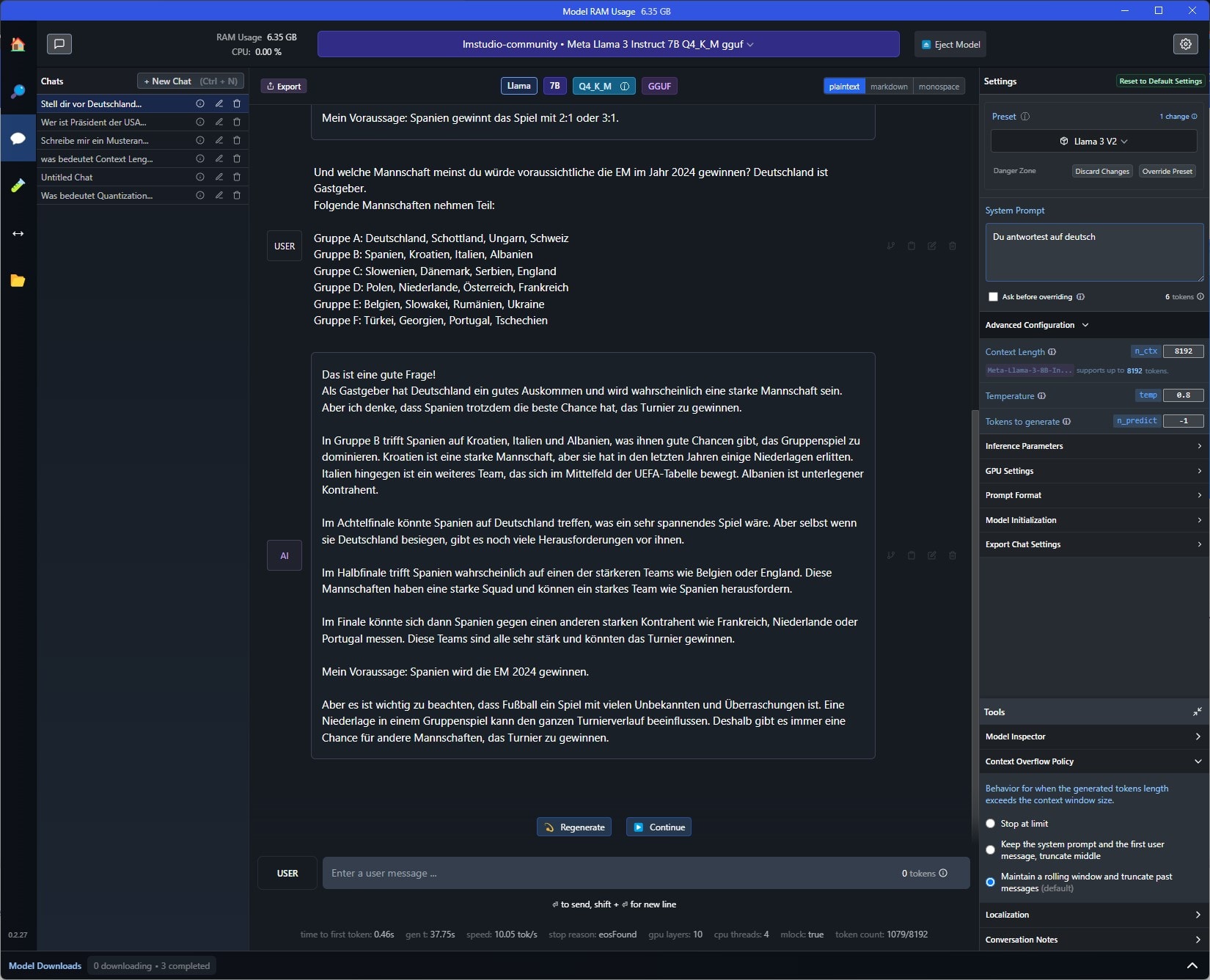
Hier der Vergleich vom kleineren Modell Meta-Llama-3-8B-Instruct-Q4_K_M.gguf mit dem größeren QuantFactory/Meta-Llama-3-8B-Instruct-GGUF auf meinem System mit Ryzen 7700X CPU und RTX 3070.
Wirklich privat?
Sendet LM Studio deine Eingaben wirklich nicht an den Entwickler? Der Entwickler schreibt hier:
„TLDR: The app does not collect data or monitor your actions. Your data stays local on your machine.“
Und dies kann ich soweit bestätigen. Es gibt bei der Eingabe von Befehlen usw. keine Netzwerkaktivität. Entsprechend werden auch keine Daten oder Eingaben an den Entwickler/Hersteller übermittelt. So ist auch eine komplette Offline-Nutzung möglich, nachdem die entsprechenden Modelle einmalig heruntergeladen wurden.
Wie gut sind die Antworten?
Die Qualität der Antworten schwankt natürlich massiv, je nach gewähltem Modell usw. Diese schwanken zwischen furchtbar und erstaunlich gut.
Nein, die lokale KI kann gerade bei komplexeren Themen nicht mit ChatGPT mithalten, aber dennoch bin ich positiv angetan.
Hier einfach mal ein paar Beispiele für Antworten auf zufällige Fragen:


Fazit: Lokale Chat-KI mit Standard-Hardware – kein Problem!
Ich hoffe, dieser Artikel war interessant und inspiriert dich, auch mal LM Studio auszuprobieren und damit etwas herumzuspielen.
LM Studio macht dir die Nutzung eines lokalen, privaten KI-Chat-Assistenten wirklich kinderleicht!
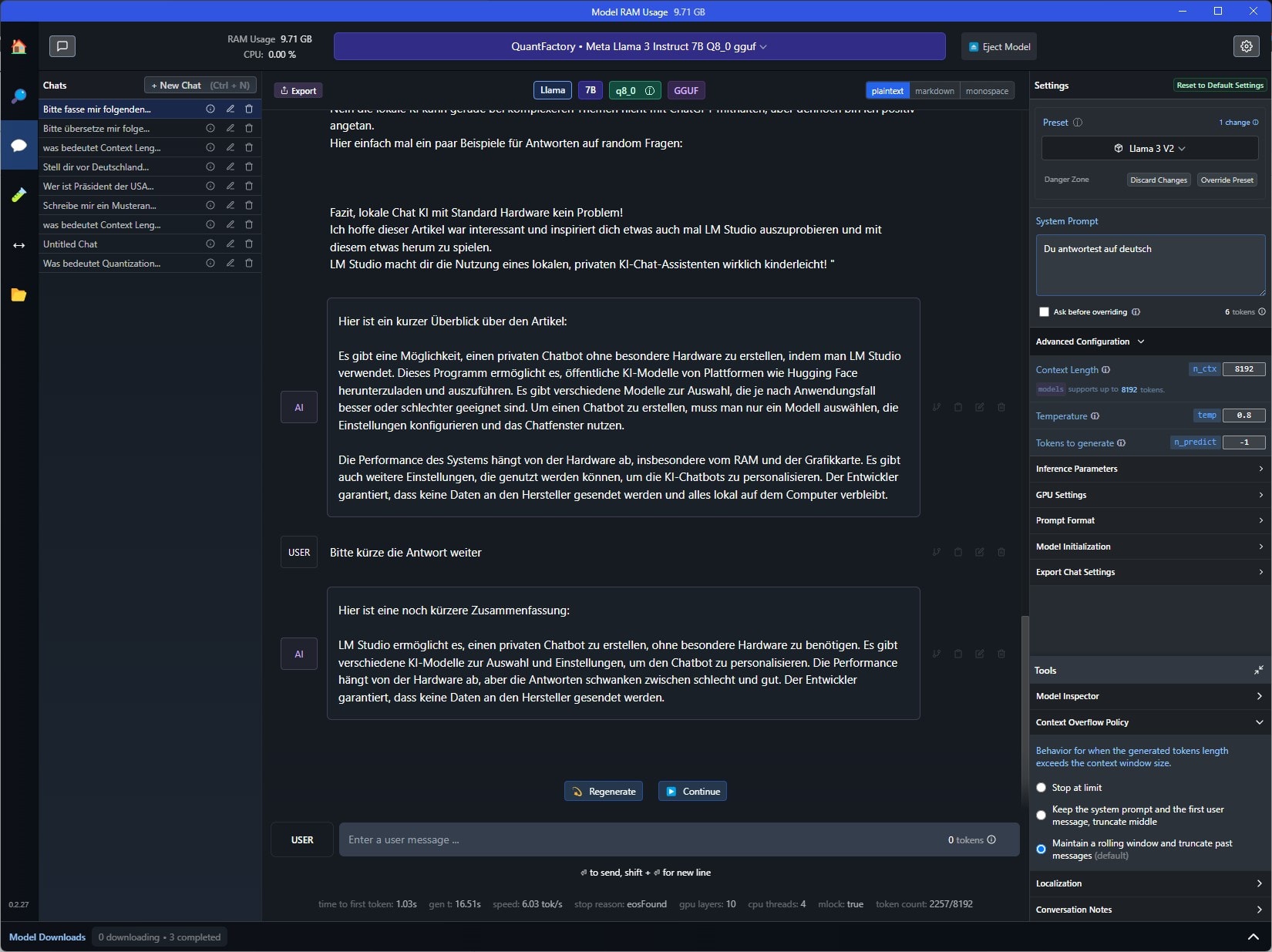
Damit entlasse ich dich dann mit einer von der KI erstellten Zusammenfassung dieses Artikels:
„LM Studio ermöglicht es, einen privaten Chatbot zu erstellen, ohne besondere Hardware zu benötigen. Es gibt verschiedene KI-Modelle zur Auswahl und Einstellungen, um den Chatbot zu personalisieren. Die Performance hängt von der Hardware ab, aber die Antworten können stark variieren. Der Entwickler garantiert, dass keine Daten an den Hersteller gesendet werden.“

Kein Kommentar, nur Dank für den soliden Artikel!
Spannender Artikel und erstaunlich, wie fortgeschritten die LM-Modelle auf einem handelsüblichen PC schon sind, das überrascht mich.